ルーレットを作る
松浦総一
2018/5/6
ルーレットを作る。
ルーレットを例として,ランダム・サンプルの特徴を理解する。
設定
sample()は引数のなかからデータをランダムに取り出す関数である。
sample(1:36,1,replace=TRUE)## [1] 13これは,1〜36から1つ取り出す,復元あり,という命令であり,1〜36のうち1つの数字が出力される。 もちろん,実行するたびに結果が分かる。
help(sample)と入力すれば,詳しい使い方が表示される(ただし英語)。
次は,1〜36の数字の中から,復元ありで,20個の数字を取り出す,という命令である。その結果,20個の数字が表示される。
sample(1:36,20,replace=TRUE)## [1] 20 13 27 13 31 20 10 18 25 10 18 16 8 23 11 28 11 36 11 8replace=TRUEをreplace=FALSEにすればどうなるか考えてみよう。
ルーレット
ルーレットを作る。ルーレットを回す回数をnとする。
n <- 1000
fair <- sample(1:36,n,replace=TRUE)ここではnに1000を代入し,1〜36の数字の中から,置き換えありで,1000個の数字を取り出している。 その結果を,fairに代入している。
ここまでで,ルーレットを1000回まわした結果をサンプルとしたデータが作成された。 それでは,1が出た回数を数えてみましょう。 sum()を用いてfair==1の個数を足し合わせる。
sum(fair == 1)## [1] 22これを試行回数nで除して,サンプルに占める1の割合を計算してみる。
sum(fair == 1)/n## [1] 0.022いろいろな統計量を表示させるときは,summary()を用いる。
summary(fair)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.00 10.00 18.00 18.45 27.00 36.00次に,サンプルの特徴を示すために,統計量とヒストグラムを書く。
hist(fair)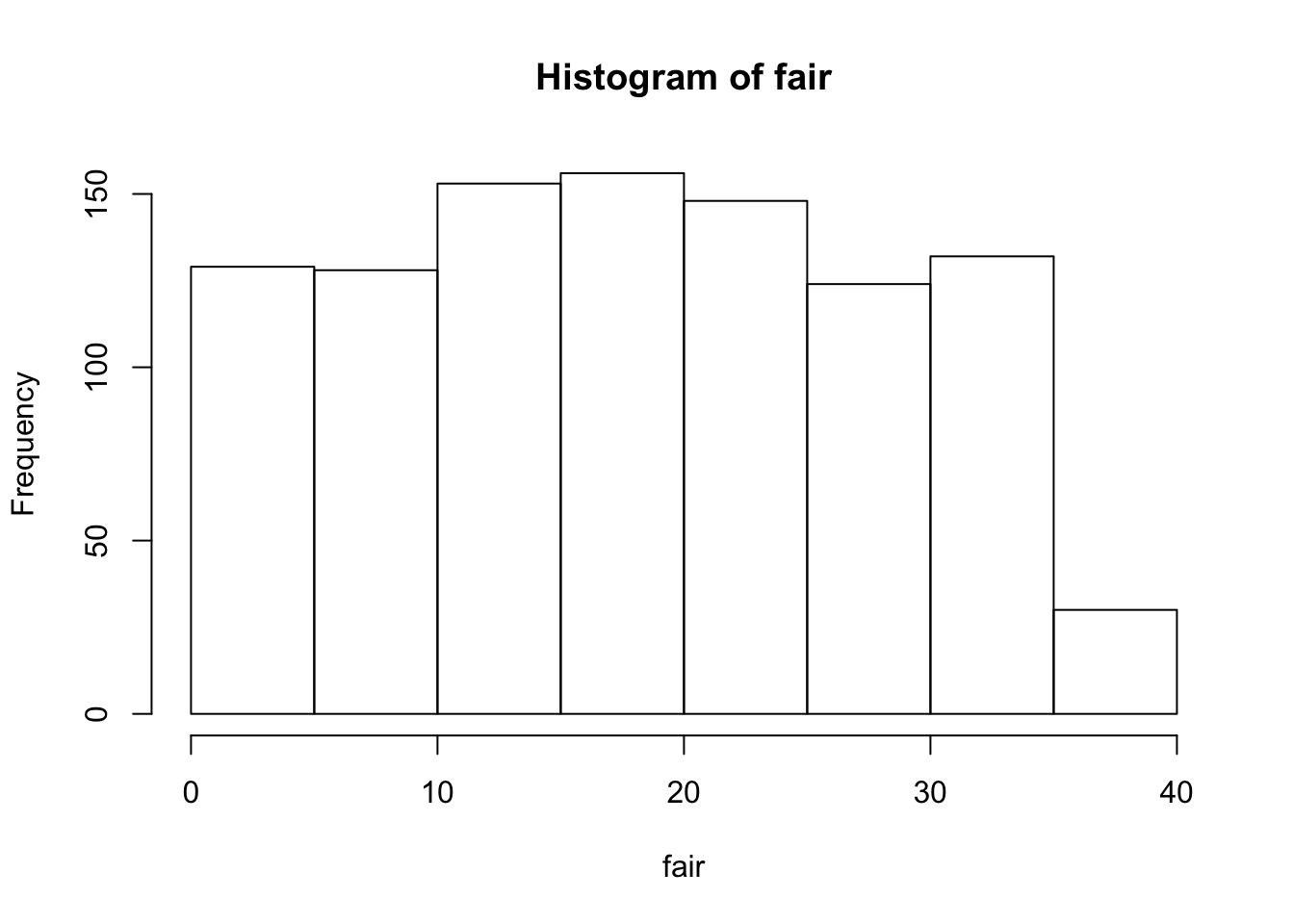
これは棒グラフではなく,度数分布表であるため,棒の高さは度数を表している。 デフォルトのままでは,幅が5刻みとなっているので,1刻みに変更する。
hist(fair,breaks=0:36) # 幅を0から36の1刻みにする。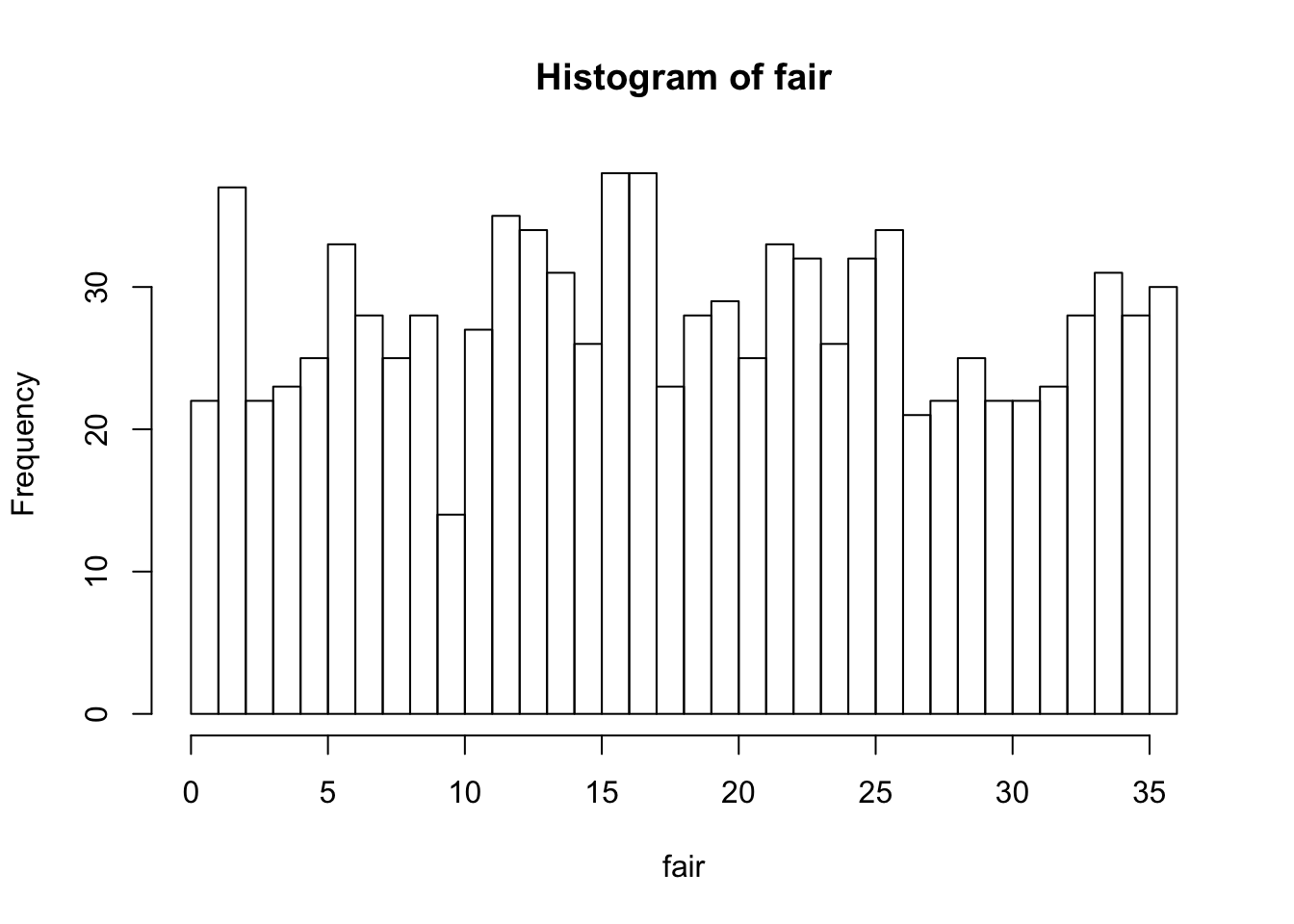
Y軸を度数ではなく,頻度確率にするためには,probability=TRUEをくっつける。
hist(fair,breaks=0:36,probability=TRUE)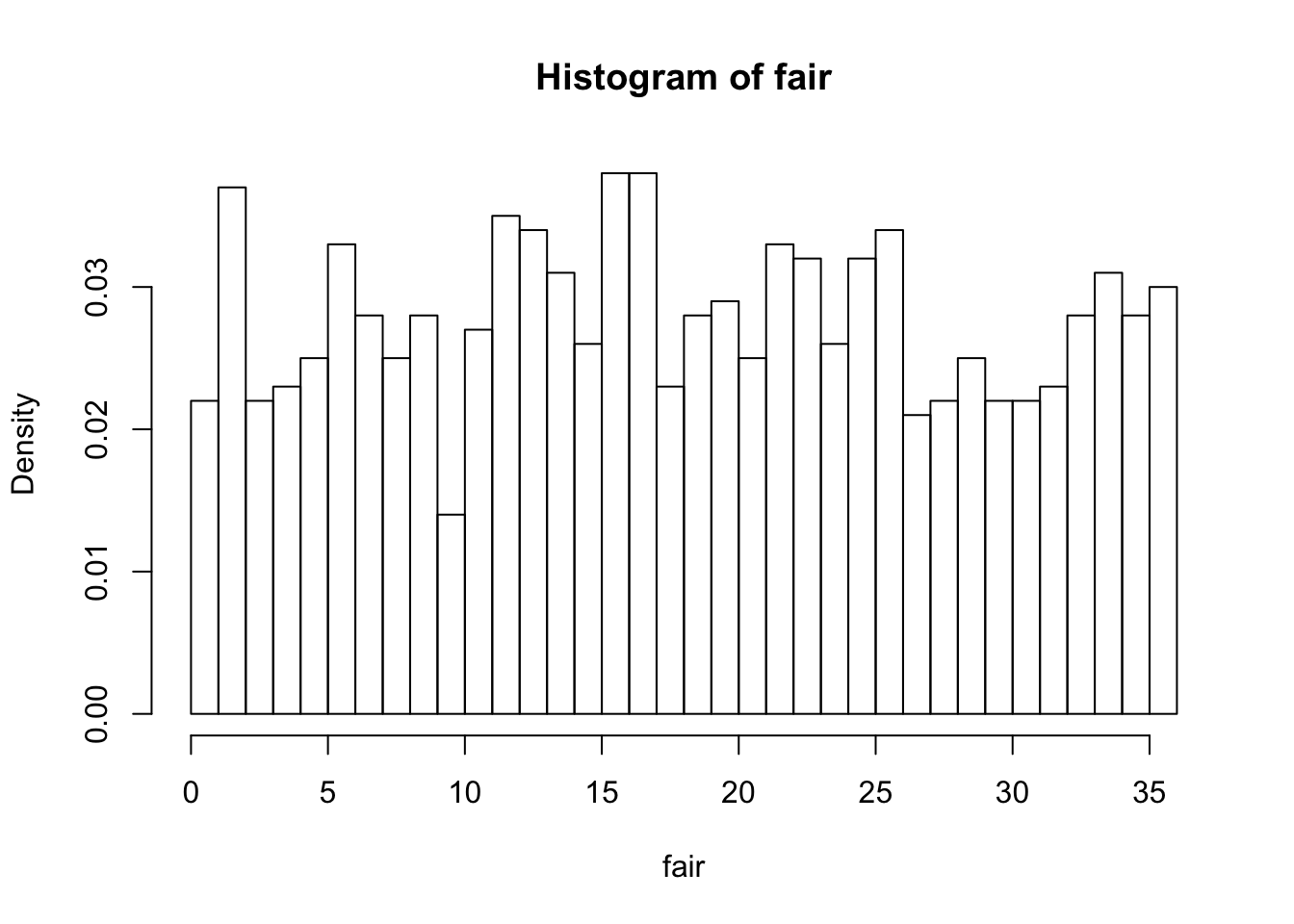
Y軸が変更されたのを確認しよう。 同様に,出現割合のヒストグラムも見てみよう。
summary(as.factor(fair))/n## 1 2 3 4 5 6 7 8 9 10 11 12
## 0.022 0.037 0.022 0.023 0.025 0.033 0.028 0.025 0.028 0.014 0.027 0.035
## 13 14 15 16 17 18 19 20 21 22 23 24
## 0.034 0.031 0.026 0.038 0.038 0.023 0.028 0.029 0.025 0.033 0.032 0.026
## 25 26 27 28 29 30 31 32 33 34 35 36
## 0.032 0.034 0.021 0.022 0.025 0.022 0.022 0.023 0.028 0.031 0.028 0.030hist(fair/n)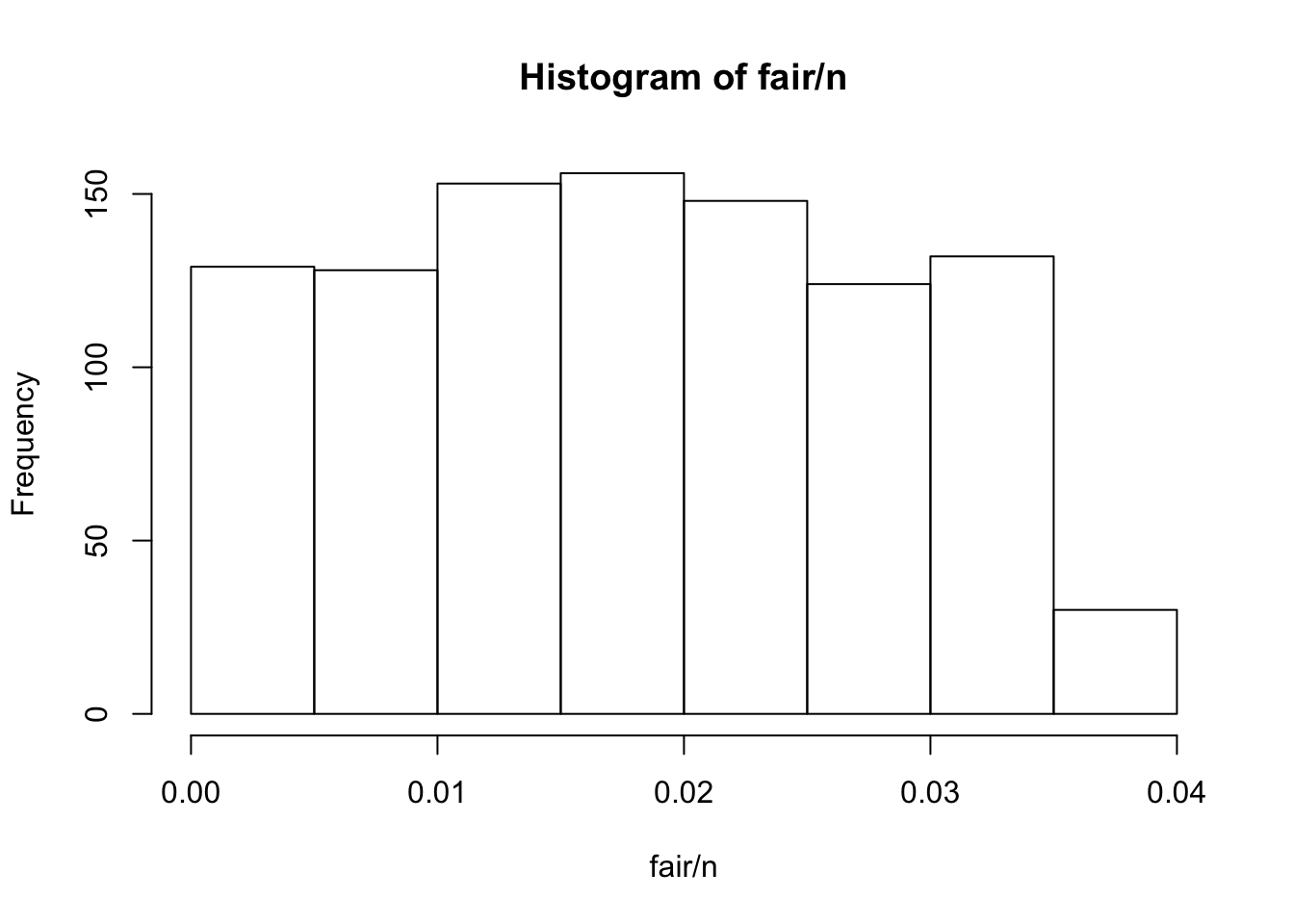
hist(fair/n,probability=TRUE)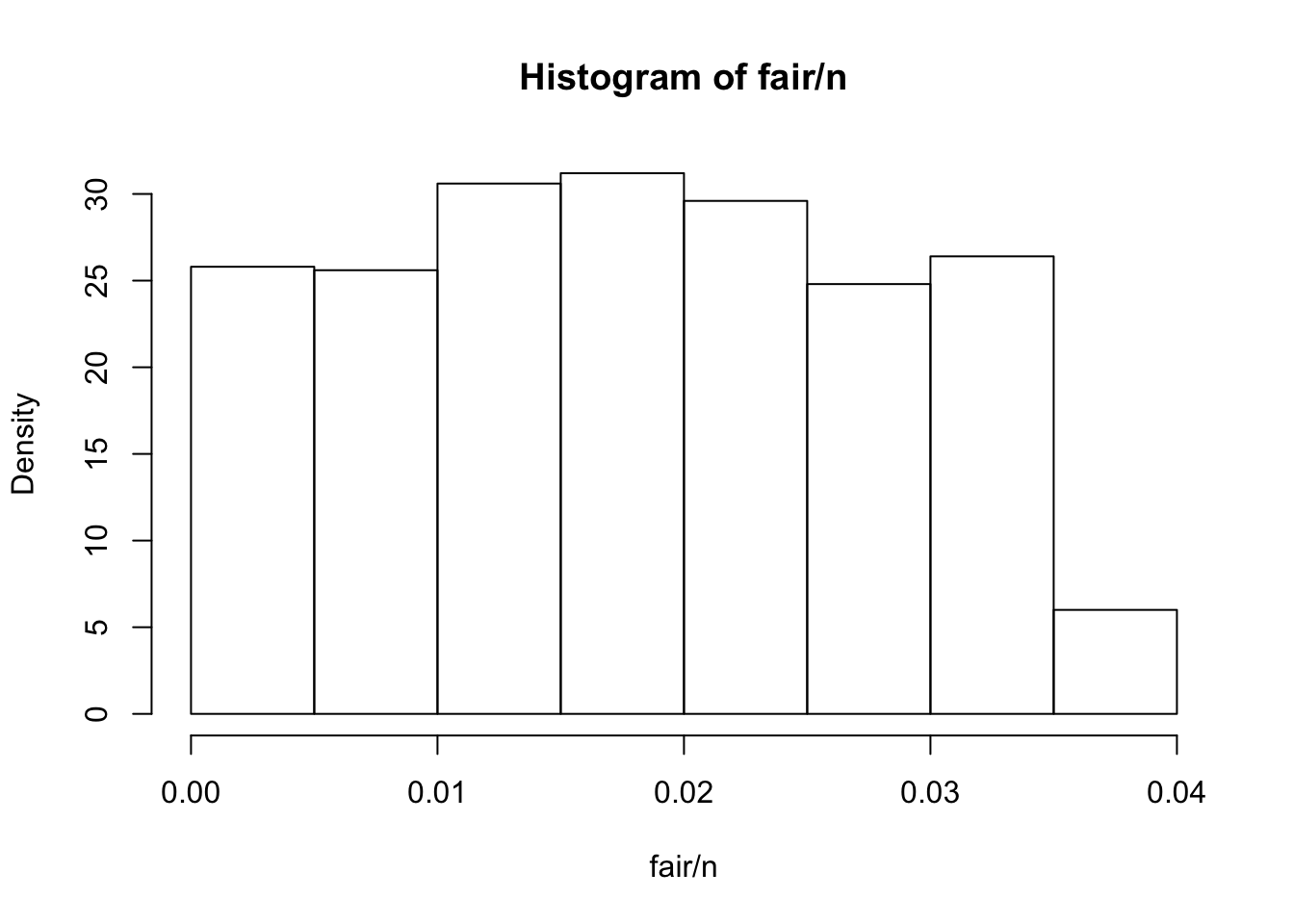
平均や中央値,分散を見たいときは,mean,median,varを使う。
mean(fair) # 平均## [1] 18.447median(fair) # 中央値## [1] 18var(fair) # 分散## [1] 104.3195四分位や最大値・最小値をみる。
quantile(fair, 0.25) #第1四分位## 25%
## 10quantile(fair,0.5) # 第2四分位=中央値## 50%
## 18quantile(fair,0.75) # 第3四分位## 75%
## 27max(fair) #最大値## [1] 36min(fair) #最小値## [1] 1quantile(fair,c(0,0.25,0.5,0.75,1)) #全部## 0% 25% 50% 75% 100%
## 1 10 18 27 36次は,このルーレットの結果をグラフする。 散布図を書く場合には,plot()を用いる。
y <- summary(as.factor(fair))/n
plot(1:36,y ,xlab="Number on Wheel", ylab="Proportion", main="Fair Wheel")
abline(a=1/36,b=0,col="blue")
probs <- rep(1/36,36)
probs## [1] 0.02777778 0.02777778 0.02777778 0.02777778 0.02777778 0.02777778
## [7] 0.02777778 0.02777778 0.02777778 0.02777778 0.02777778 0.02777778
## [13] 0.02777778 0.02777778 0.02777778 0.02777778 0.02777778 0.02777778
## [19] 0.02777778 0.02777778 0.02777778 0.02777778 0.02777778 0.02777778
## [25] 0.02777778 0.02777778 0.02777778 0.02777778 0.02777778 0.02777778
## [31] 0.02777778 0.02777778 0.02777778 0.02777778 0.02777778 0.02777778## +/- 1.96 std deviations
sdline.up <- probs + 1.96*sqrt((probs)*(1-probs)/n)
sdline.down <- probs - 1.96*sqrt((probs)*(1-probs)/n)
points(1:36,sdline.up,col="green",type="l")
points(1:36,sdline.down,col="green",type="l")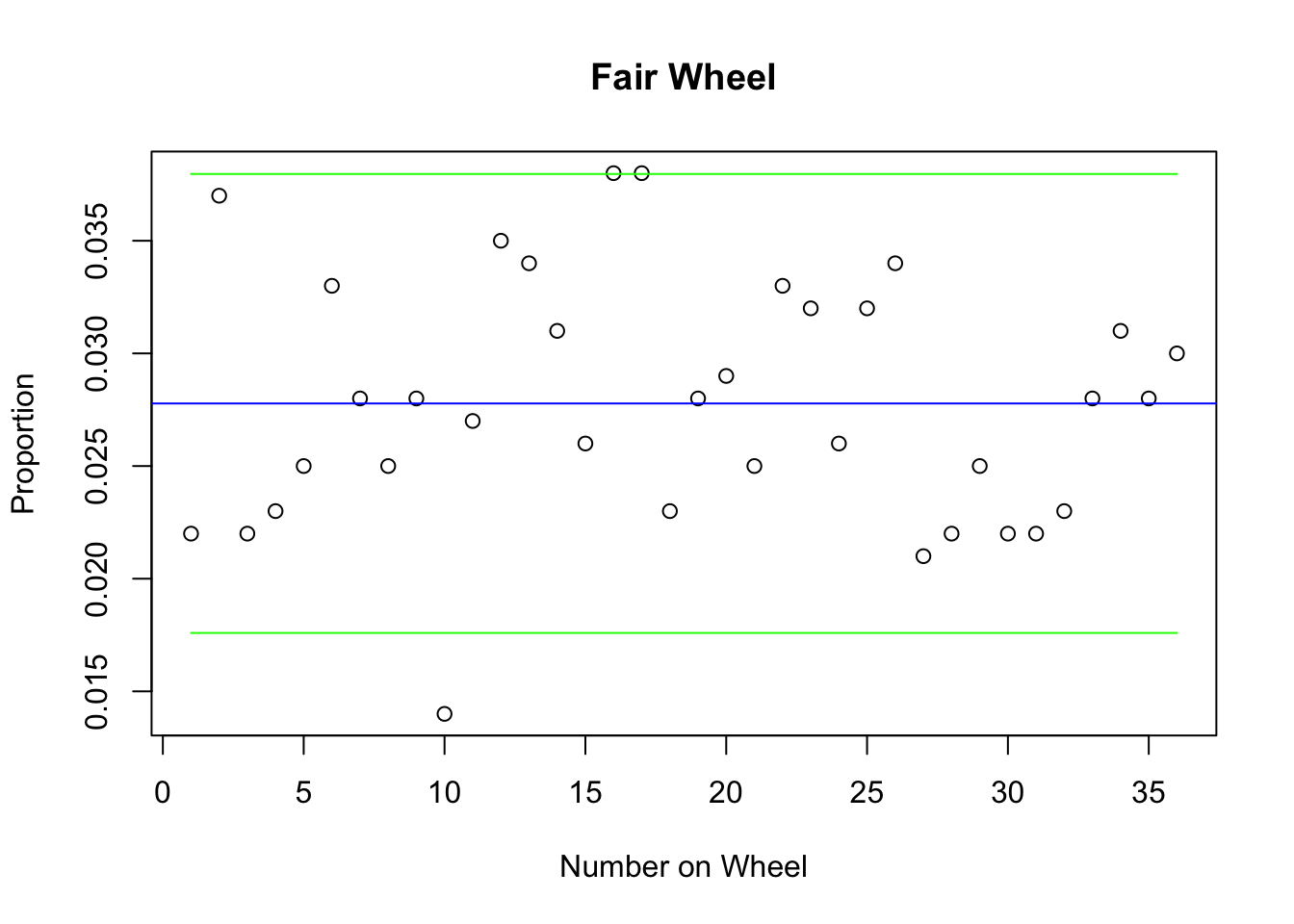
1標準偏差を超えた頻度と割合
sum((abs(y-1/36))>1.96*sqrt((probs)*(1-probs)/n)) # how many freqs outside## [1] 3sum((abs(y-1/36))>1.96*sqrt((probs)*(1-probs)/n))/36 # % freqs outside ## [1] 0.08333333次のコマンドが何を意味するのかも考えてみよう。
sum(1-(fair %% 2) ) #how many are even (how does this work?)## [1] 509sum(1-(fair %% 2) )/n #what proportion are even## [1] 0.509練習として,10000回ルーレットを回したとき,何が起こるか,試してみよう。
確率がゆがんでいるルーレット
probs <- (1:36)/666 #確率を設定
n <- 10000
unfair <- sample(36,n,replace=TRUE,probs)
hist(unfair,breaks=0:36) # ヒストグラム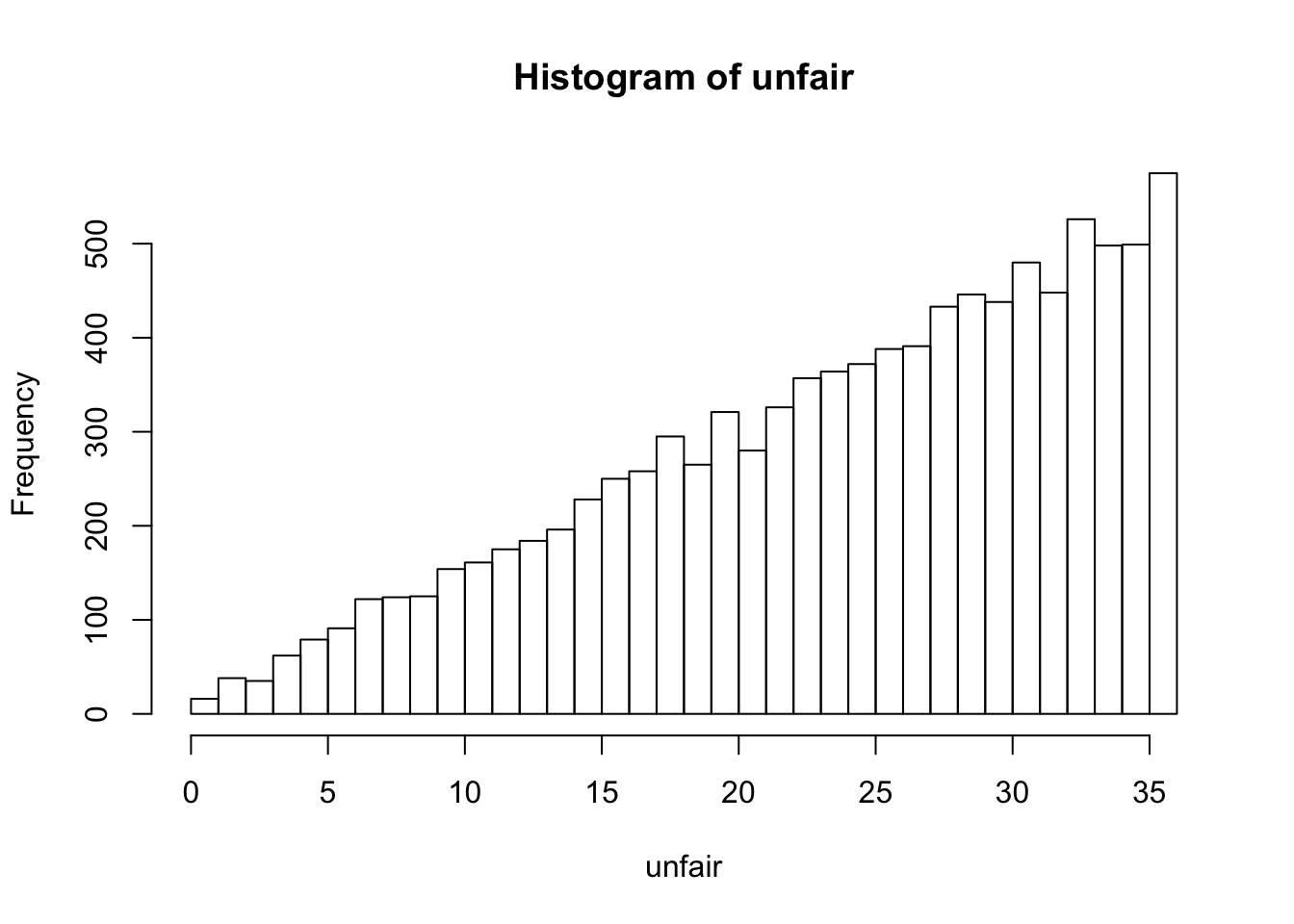
hist(unfair,breaks=0:36,probability=TRUE) # ヒストグラム
2つのグラフの差を確認しよう。
summary(as.factor(unfair))## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
## 16 38 35 62 79 91 122 124 125 154 161 175 184 196 228 250 258 295
## 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
## 265 321 280 326 357 364 372 388 391 433 446 438 480 448 526 498 499 575summary(as.factor(unfair))/n## 1 2 3 4 5 6 7 8 9 10
## 0.0016 0.0038 0.0035 0.0062 0.0079 0.0091 0.0122 0.0124 0.0125 0.0154
## 11 12 13 14 15 16 17 18 19 20
## 0.0161 0.0175 0.0184 0.0196 0.0228 0.0250 0.0258 0.0295 0.0265 0.0321
## 21 22 23 24 25 26 27 28 29 30
## 0.0280 0.0326 0.0357 0.0364 0.0372 0.0388 0.0391 0.0433 0.0446 0.0438
## 31 32 33 34 35 36
## 0.0480 0.0448 0.0526 0.0498 0.0499 0.0575作図してみる。
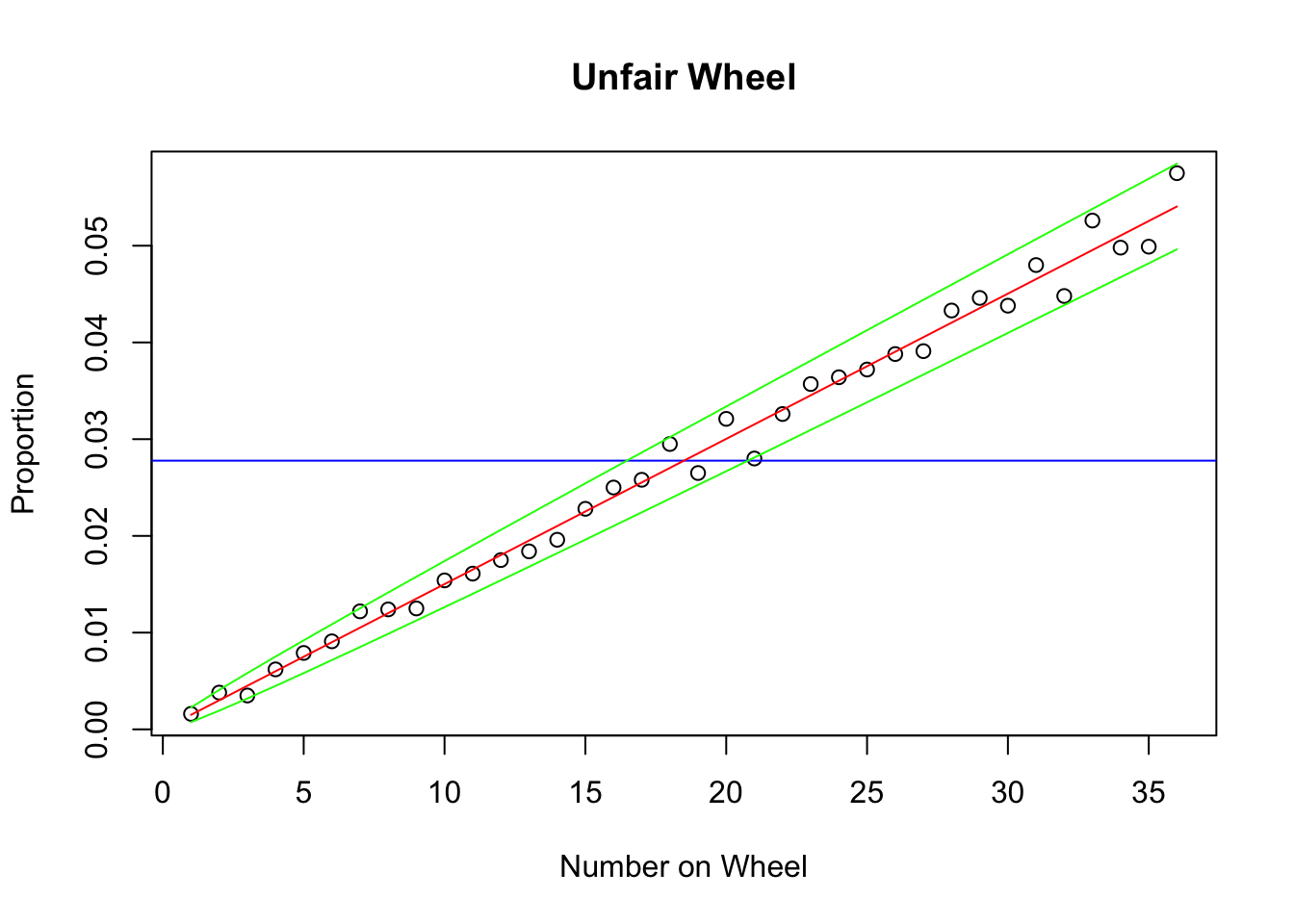
y <- summary(as.factor(unfair))/n
plot(1:36,y,xlab="Number on Wheel",
ylab="Proportion",main="Unfair Wheel")
abline(a=1/36,b=0,col="blue")
points(1:36,probs,col="red",type="l")
## +/- 1.96 標準偏差
sdline.up <- probs + 1.96*sqrt((probs)*(1-probs)/n)
sdline.down <- probs - 1.96*sqrt((probs)*(1-probs)/n)
points(1:36,sdline.up,col="green",type="l")
points(1:36,sdline.down,col="green",type="l")